
Serving a PyTorch Model in C++ Using LibTorch
Building an HTTP server in C++ to handle JSON requests and run inference with a PyTorch model using cpp-httplib and nlohmann-json.

When deploying deep learning models in production, minimizing latency and reducing dependencies are critical. This blog explores how to serve PyTorch models trained in a Python environment using libtorch in C++, completely eliminating the need for Python at inference time. By leveraging libtorch's native C++ API, we achieve ultra-fast performance with minimal overhead, avoiding the complexities of asynchronous execution while keeping the final deployment artifact extremely lightweight. We'll also discuss how Docker’s multi-stage builds can further reduce the image size, making this approach ideal for resource-constrained environments or high-performance applications.
This blog explores deploying a PyTorch model trained in Python to a C++ environment using TorchScript. We’ll demonstrate how this approach enables high-performance inference and seamless integration into C++ systems. Our example involves setting up an HTTP server to handle POST requests, perform inference using the model, and accept and return predictions in JSON format. Memory safety and graceful server shutdown mechanisms will also be covered.
The model being used is a trained one exported in my other blog. Any torch::jit model, torch.jit.script or torch.jit.trace, from pytorch should be fine. You may checkout the sections exporting-the-model and notes-on-exporting from the above blog for more details on exporting. I will skip the exporting part for brevity.
Prerequisites
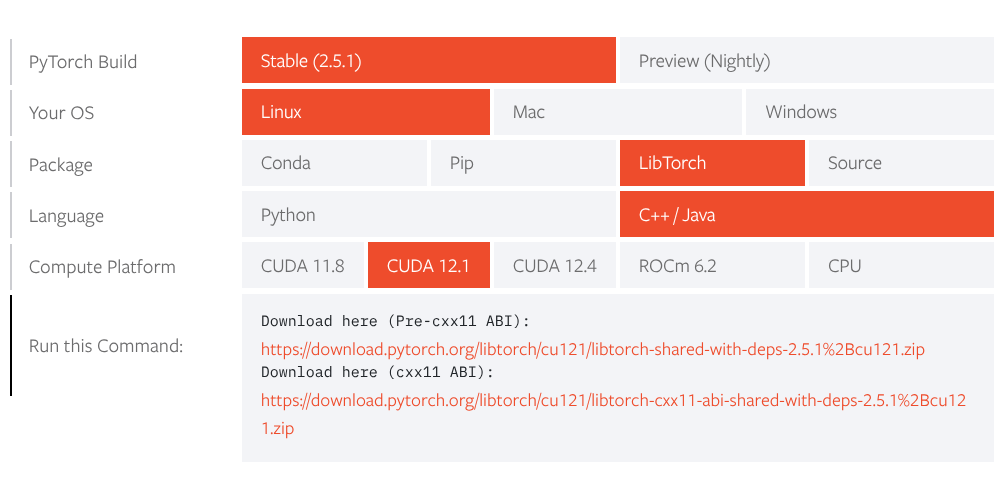
libtorch: Download libtorch for your architecture (GPU or CPU), with or without dependencies as required by your environment, from official website. I have downloaded for CUDA-12.1 and with dependencies. At the time of writing, downloaded for CUDA=12.1, libtorch for pytorch 2.5.1 is what was available. Unzip the download.
cpp-httplib: Download the
httplib.hfile from the cpp-httplib GitHub repository
nlohmann-json: Download the
includeandsingle_includedirectories from the nlohmann-json GitHub repository.



Project Structure
Organize your project as follows,
$ tree -L 2 libtorch-cpp-inference/
├── build_and_run.sh
├── main.cpp
├── my_model_scripted.pt
├── CMakeLists.txt
├── README.md
├── cpp-httplib
│ └── httplib.h
├── libtorch
│ ├── bin
│ ├── build-hash
│ ├── build-version
│ ├── include
│ ├── lib
│ └── share
├── nlohmann-json
│ ├── include
│ └── single_includeStep 1: Main Function
The main function is the entry point and it performs the following things in sequence:
Load the model from disk and put it only in evaluation model to not have gradients tracked. Below shows the basic way to do the same.
#include <torch/script.h> torch::jit::script::Module model = torch::jit::load("my_model_scripted.pt");Let’s actually make this a bit better by also handling catching when the input path doesn’t point to a model or it is not found. You may add more logic to this or even choose to completely skip this part.
// Load the model from the its file-path torch::jit::script::Module load_model(const std::string &model_path) { try { return torch::jit::load(model_path); } catch (const c10::Error &e) { std::cerr << "Error loading model: " << e.what_without_backtrace() << std::endl; std::exit(EXIT_FAILURE); } }And this function will be called instead inside the main function.
Start the server to serve requests, process input and output data. For all that, let’s have a function call here with the model being the input, inside the main function and we will talk about what goes inside this in detail in a bit.
Exit by returning 0 or you may also return
EXIT_SUCCESS.
C++ Implementation:
#include <torch/script.h>
#include <torch/nn/functional/activation.h>
int main() {
// Path to the model artifact as a string; For me, only full path helped, relative path never worked.
std::string model_path = "/home/naveen/Projects/libtorch-cpp-inference/my_model_scripted.pt";
// Load the model
torch::jit::script::Module model = load_model(model_path);
// Set the model to evaluation mode
torch::NoGradGuard no_grad;
model.eval();
// Run the server
run_server(model);
return EXIT_SUCCESS;
}Step 2: Delving into server logic - run_server function
The run_server function will encapsulate all server-related tasks in the following order,
Create an HTTP server instance, cpp-httplib library will be used for the HTTP server.
#include "cpp-httplib/httplib.h" http_server = std::make_unique<httplib::Server>();For thread-safety, the server needs to be declared as a global variable,
// Declare the server as a global unique pointer for cleanup purposes std::unique_ptr<httplib::Server> http_server;cpp-httplib is a header only library, since you are likely (you should actually) to also use a reverse-proxy and other things like authentication should be taken care of, by something else before the payload reaches this code in a production setting.
Define a POST route (
/predict)that accepts JSON inputs and also the returns the predictions in JSON responses.A copy of the trained model needs to be taken here for thread safety, Since the
torch::jit::script::Moduleclass is not thread-safe (check https://github.com/pytorch/pytorch/issues/15210 for more on this).And for every HTTP POST request, parsing the input, make it a torch-tensor, forward pass, output manipulation etc. exist, so, let’s encapsualte all that into a function and we will be calling it from here which does the prediction using the jit-scripted model. This function will be called with the jit-scripted model, httplib’s request and response as inputs.
After the server setup and functioning is defined, setup for graceful termination need to be taken care of. For that, we need to handle
SIGINTandSIGTERMand perform graceful shutdown, when the application receives one of those signals, instead of abrupt termination. This prevents resource leaks or dangling threads, which are crucial for long-running services, like this inference for example.For that, let’s have a global flag which indicates if the server needs to be shut down. And for shutdown, it would be cleaner to print to stdout that server is beign shutdown, then does the termination. All of this needs to be performed for two seperate commands, so, let’s put all of this inside a function and perform these actions when either of those signals are received.
// A global flag to indicate whether the server should stop std::atomic<bool> to_be_stopped{false}; // Signal handler function for graceful server shutdown void signal_handler(int signal) { std::cout << "\nReceived signal " << signal << ". Shutting down server...\n"; to_be_stopped.store(true); http_server->stop(); }
Setup for the server part is now done. Let’s print a message to stdout indicating that the server is being started and start the server on a port.
C++ Implementation:
#include "cpp-httplib/httplib.h"
// Setup and run the server
void run_server(const torch::jit::script::Module &torch_module) {
// Create an HTTP server
server = std::make_unique<httplib::Server>();
// Define the route to handle POST requests
server->Post("/predict", [&](const httplib::Request &req, httplib::Response &res) {
torch::jit::script::Module torch_module_copy = torch_module; // Create a copy for thread safety
do_prediction(torch_module_copy, req, res);
});
// Register the signal handler for graceful termination
std::signal(SIGINT, signal_handler);
std::signal(SIGTERM, signal_handler);
// Start the server on port 8080
std::cout << "Server running on port 8080...\n";
server->listen("0.0.0.0", 8080);
}Step 3: Now, the prediction logic (do_prediction)
As mentioned above, The do_prediction function, takes as input the jit-scripted model, input payload and response instances.
Input will be JSON with `Content-Type=application/json`, which will have one key `input_matrix` and its value will be list of lists with our 3D matrix containing the input for prediction or inference, you may even pass batch of inputs here.
In JSON, list of lists, using square-brackets, is the only supported way to send multi-dimensional arrays. And Cpp does not have a native way to handle json data, hence a third-party library (nlohmann/json) will be used. However, C++ uses curvy-brackets for arrays and using {} inside the json in not allowed. Hence, the list-of-lists from Json input needs to be recursively read, element by element, into a Cpp array, after which it can be converted to a torch-tensor, like so,
#include "nlohmann-json/single_include/nlohmann/json.hpp" // to enable json data-types in the code using json = nlohmann::json; // Convert nested JSON array to tensor recursively at::Tensor json_to_tensor(const json &input_json) { if (input_json.is_array()) { // Parse numeric arrays std::vector<at::Tensor> out_tensor; for (const auto &item : input_json) { out_tensor.push_back(json_to_tensor(item)); } return at::stack(out_tensor); } // because of the recursion involved, when the recursion reaches lowest level, // it needs to be managed accordingly too else if (input_json.is_number()) { // Convert a single number into a scalar tensor return torch::tensor(input_json.get<float>()); } else { // Throw an exception for invalid input throw std::runtime_error("Unexpected non-numeric value in JSON array"); } }YES, this is recursive! However, if you choose to not do that, you will have to send some other
Content-Type, notapplication/json, you may consider using binary payload with Content-Type likeapplication/octet-streamor even “.bin” files to be able to read it to a tensor without a loop. I will avoid all the complexity for now and stick to using loops and application/json, since you will be customising the code from the blog for your use case any way.
Then reshape the tensor to {1,3,4,4} (or another size, if you are doing batch inference) and pass it through the model for a forward pass and extract the output to a tensor.
Now, to be able to add this to the outgoing json, numbers in the tensor need to be copied to a Cpp array.
In Python3, for example, `arr2 = arr1[:]`, `arr2 = arr1[0:]` `arr2=[0:-1]` allows us to copy, but it isn’t as straightforward with Cpp, so, let’s first get the pointers to be able to get the first and last indexes of the tensor,
// This line gets a raw pointer (r_ptr) to the underlying data in the tensor model_preds, where the data type of the elements in the tensor is float. Tensor data in PyTorch is stored in a compact, continuous memory layout (often on the CPU or GPU). This line retrieves a pointer to that data in order to interact with it directly, for example, to copy the data into a C++ std::vector or perform other operations. auto r_ptr = model_preds.data_ptr<float>(); // This line computes the number of elements in the tensor model_preds using the .numel() method. Knowing the total number of elements is necessary to iterate over or copy the tensor's data.For example, if model_preds has a shape of (1, 3, 4, 4), then the total number of elements (numel) is 1 × 3 × 4 × 4 = 48. auto tensor_size = model_preds.numel();Now, create a vector, named `output_array` from the tensor data, using those two values,
std::vector<float> output_array(r_ptr, r_ptr + tensor_size);
Then define output json with a key called `output_preds`, fill the value with the output from forward pass and return.
C++ Implementation:
// Handle prediction requests for one sample
void do_prediction(torch::jit::script::Module &torch_model, const httplib::Request &req, httplib::Response &res) {
try {
// Parse the input string to JSON
json input_payload = json::parse(req.body);
// Validate the input matrix
if (!input_payload.contains("input_matrix") || !input_payload["input_matrix"].is_array()) {
json error_json; // Initialize an empty variable and fill it with msg
error_json["error"] = "Missing `input_matrix` key in JSON request or it is not an array.";
res.status = 400; // Then set the outgoing object's status to 400
res.set_content(error_json.dump(), "application/json"); // now dump the above json to the outgoing object along with Content-Type and return
return;
}
// Parse the input list
at::Tensor input_tensor = json_to_tensor(input_payload["input_matrix"]);
// Reshape tensor to match expected model dimensions (e.g., 1x3x4x4 for this example)
try{
input_tensor = input_tensor.view({1, 3, 4, 4});
}
catch (const std::exception &e) {
json error_json; // Initialize an empty variable and fill it with msg
error_json["error"] = "Failed to shape input to torch-tensor {1, 3, 4, 4}";
res.status = 400; // Then set the outgoing object's status to 400
res.set_content(error_json.dump(), "application/json");
// now dump the above json to the outgoing object along with Content-Type and return
return;
}
// Perform model inference
std::vector<torch::jit::IValue> inputs{input_tensor};
at::Tensor model_preds = torch_model.forward(inputs).toTensor();
// Convert torch::Tensor to a C++ vector
// Get the pointer to the tensor data and the size of the tensor
auto r_ptr = model_preds.data_ptr<float>();
auto tensor_size = model_preds.numel();
// Create a vector from the tensor data
// This line creates a C++ standard vector (std::vector) named result, initialized with the data from the tensor model_preds.
// It uses the pointer r_ptr as the starting position and r_ptr + tensor_size as the ending position to copy the entire data buffer into the vector.
// The std::vector will contain all the float values from the tensor, in the same order as they appear in memory.
std::vector<float> result(r_ptr, r_ptr + tensor_size);
// Make a new JSON object to send
json out_payload;
out_payload["output"] = result;
// Send the JSON response
res.set_content(out_payload.dump(), "application/json");
} catch (const std::exception &e) {
json error_json;
error_json["error"] = "Server error: " + std::string(e.what());
res.status = 500;
res.set_content(error_json.dump(), "application/json");
}
}Step 4: Build and Run
Here’s the “CMakeLists.txt” file inspired heavily from libtorch docs,
cmake_minimum_required(VERSION 3.18 FATAL_ERROR)
# Project title and version; this will also become the executable after the build is done.
project(proj_torch_inference VERSION 1.0)
# path to unzipped `libtorch` must be an absolute path.
# Specify the path to libtorch if not passed as a command-line argument
# In particular, setting `DCMAKE_PREFIX_PATH` to something like `../../libtorch` will break in unexpected ways.
set(CMAKE_PREFIX_PATH "${CMAKE_SOURCE_DIR}/libtorch/")
# Find the required packages
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
# Add the executable
add_executable(torch_inference main.cpp)
# Link against Torch library
target_link_libraries(torch_inference PRIVATE "${TORCH_LIBRARIES}")
# Set the C++ standard for the torch_inference target
set_property(TARGET torch_inference PROPERTY CXX_STANDARD 17)
set_property(TARGET torch_inference PROPERTY CXX_STANDARD_REQUIRED ON)Now, generating the build files,
$ cmake -S $PWD/ -B $PWD/build/
-- Configuring done
-- Generating done
-- Build files have been written to: /home/naveen/Projects/libtorch-cpp-inference/buildNow, compilation and generating the executable,
$ cd build/ && make
[ 50%] Building CXX object CMakeFiles/torch_inference.dir/main.cpp.o
[100%] Linking CXX executable torch_inference
[100%] Built target torch_inferenceNow, let’s run the generated executable. This should start the server,
$ ./torch_inference
Server running on port 8080...Open a new terminal session and send a few requests using curl,
$ curl --location 'http://0.0.0.0:8080/predict' \
--header 'Content-Type: application/json' \
--data '{"input_matrix": [[[[0.3879, 0.2045, 0.2850, 0.4871],
[0.2640, 0.4860, 0.9306, 0.6901],
[0.2830, 0.3316, 0.8404, 0.9194],
[0.9132, 0.5200, 0.5266, 0.5509]],
[[0.6306, 0.6859, 0.6948, 0.9534],
[0.4894, 0.8682, 0.9207, 0.2763],
[0.5308, 0.1817, 0.1540, 0.4378],
[0.1836, 0.0265, 0.6769, 0.1860]],
[[0.1508, 0.6728, 0.4751, 0.7453],
[0.4481, 0.2678, 0.7070, 0.4812],
[0.0802, 0.7102, 0.2592, 0.7463],
[0.0631, 0.5948, 0.9220, 0.1469]]]]}'
{"output_preds":[0.3166750371456146,0.13776813447475433,0.20831984281539917,0.3372369110584259]}This is the same example from the notebook from the blog linked above.
Improvements using this Cpp apprach for inference:
You may have noticed that the file we executed, ./torch_inference, is the only artifact required for deployment—there’s no need to ship the entire libtorch folder, a server, or JSON-handling dependencies. After compilation, this single binary file is all that’s necessary, and in this case, it was under 3MB. In contrast, deploying a PyTorch model in Python would require bundling PyTorch itself along with all its dependencies from requirements.txt, which can easily exceed a few hundred megabytes. Additionally, C++ offers improved inference speed compared to Python, making it a compelling choice for performance-critical applications.
If you are deploying in a containerized environment, you can leverage Docker’s multi-stage builds to handle compilation separately and copy only the final binary into the image. This approach significantly reduces Docker image size, minimizing storage and deployment overhead. Even outside containerized deployments, the final artifact remains exponentially smaller than a Python-based solution while also offering performance advantages.
Limitations with the Cpp approach for inference:
The main drawbacks of using C++ for model inference include:
Development Complexity: C++ is a more complex language than Python, requiring greater effort for development and debugging.
Reduced Flexibility: If your application depends on specific Python libraries (e.g., Hugging Face’s tokenizers), integrating them into a C++ pipeline can be challenging.
Compatibility Challenges: Ensuring smooth deployment across different environments can sometimes be trickier compared to Python’s package-managed ecosystem. Take a look at the issue 67902 on pytorch’s github repo for example.
Despite these trade-offs, if your priority is efficiency, minimal deployment size, and faster inference, embedding PyTorch models in C++ using libtorch is a highly effective approach.
Skipped for brevity:
Note that all of this code is run on CPU, remember to cast the tensors to GPU if you are in a CUDA environment.
You may reduce the floating point precision of the output for Json output as needed, but for now, I’m skipping it.
You may split the functions into, may be, an utils.cpp file too, but that also requires me to write utils.h file. So, to not make the blog any longer than it is now, I will skip it. However, you should modularize your code.
Adding logging is also up to you completely, since the aim of this blog is to demonstate serving a jit-scripted torch model.
Thanks for reading!